



2.2Adaboost算法
20世纪90年代,集成学习开始了机器学习的多模型方法研究,其中Adaboost算法是典型代表。AdaBoost算法即自适应性Boosting算法。基本思想是选取若干弱分类器,组合成强分类器。
对于一个标准的人脸样本,一般来说,正面人脸眼睛部分灰度值总是要比脸颊的上半部灰度值要大,两眼的灰度总是要比两眼中间的鼻梁上部的灰度值要大等。Haar-like特征可以用来描述这些人脸特征,如图3所示。AdaBoost算法以Haar-like矩形特征为输入训练人脸分类器,首先采集“人脸”和“非人脸”样本,样本归一化之后计算样本的积分图像,然后提取样本图像中的矩形特征。一个矩形特征就对应一个弱分类器。算法采用具有两个叶节点的二叉树分类器作为弱分类器的基本形式
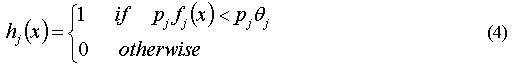
其中hj(x)是弱分类器,fj(x)是矩形特征,θj是阈值,pj控制不等号的方向,取值为±1。将检测样本的特征值与阈值θj进行比较,hj(x)为1表示人脸,否则为“非人脸”。

图3 Haar-like特征
Haar特征很多,因此会构造大量弱分类器,从中选取分类错误率最低的若干个弱分类器,同时将有效特征进行提升,构造强分类器。多个强分类器进行级联,构成级联强分类器,逐级祛除“非人脸”区域,这样提高了检测效率。
然而Adaboost算法依赖于Harr-like矩形特征,矩形特征会带来灰度分布类似于人脸的误检测,如图4所示。

图4 Adaboost算法引入的误检测






共0条 [查看全部] 网友评论