



关键词:多场景;主成分分析;K-means聚类算法
Abstract: The steel production process is long, and the production process involves many types of energy media. During production, there are various scenarios that affect the normal production rhythm. In this paper, through the scene analysis of the steel production process, the principal component analysis method is used to achieve the purpose of data dimensionality reduction, and then the method of extracting typical scenes through the K-means clustering algorithm. The established scenes include normal production scenes and maintenance Scenes, accident scenes. Finally, the actual production data of a steel plant was analyzed to verify the validity of the model.
Key words: Multiple scenes; Principal component analysis; K-means
1 引言
钢铁工业是一个能源种类繁多且节能潜力大的行业,目前我国钢铁行业能耗占比较高,节能潜力大,随着工业进步和智能制造的要求越来越迫切,通过对钢铁生产多场景的分析与建模,可以对钢铁企业的生产及计划安排提供科学性的指导,提高钢铁企业生产的连续性和降低生产成本。
目前针对钢铁企业生产多场景问题的相关论文,在相关网站很难查阅到。随着钢铁企业的发展,我国钢铁企业的发展状况发生了很大的变化,生产过程降低能耗是降低成本的重要手段,蔡九菊[1]和陆钟武[1]等学者描述了钢铁企业物质流和能量流的相互关系来分析节能。孙彦广[2]提出了基于能量流网络仿真的钢铁工业多能源介质优化调配来实现多介质调配来降低能耗,其中描述了多介质多场景的情况。唐立新[3]等学者提出了能源介质平衡与优化调度的方法来达到节能的目的。针对生产过程的多场景因素也被提到研究课题上来,对场景处理一般用场景分析法,场景分析是处理不确定问题性问题的一种有效方法[5]。本文中这些多场景因素包括生产计划的变化、检修计划的变化、能源价格的波动、生产过程事故情况等因素,对这些影响因素产生的场景建立具有代表性的场景模型,可以对生产状况提前预知,来减少能源损耗。
本文采用对实时生产数据进行采样的方法,得到大量的场景数据[4],然后对这些采样得到的数据进行数据预处理,删除不合理的数据以减少对建模的影响。文章中采用主成分分析的方法,来进行数据降维以达到特征提取的目的。本文采用标准化方法的主成分分析,这样能很大程度的减少数据的信息量损失,然后求相关系数矩阵,得到不为0的特征值,选取特征值累计贡献率超过一定百分比所对应的数据,已达到对多维度多尺度的典型数据进行特征提取的目的。然后使用k-means聚类算法,对典型场景集进行建模。
2 多能源介质系统模型
钢铁生产过程中涉及能源介质种类多、生产过程复杂、生产过程会遇到多种场景,因此本文以某钢厂为对象建立模型,根据该企业的实际能源介质生产数据,建立多能源介质的多场景调度模型。
某钢厂能源系统如附图所示。设备最左侧由上到下分别为高炉、焦炉、转炉,中间部分为锅炉,最右侧为蒸汽系统,有S1、S2、S3,三种不同等级的蒸汽,煤气柜部分分别存储高炉、焦炉、转炉产生的煤气。电厂由汽轮机组成。高炉、焦炉、转炉,三者分别产生三种不同的煤气存储到煤气柜中,有高炉煤气(BFG)、焦炉煤气(COG)、转炉煤气(LDG)。产生的煤气一部分供给给锅炉产生蒸汽,产生的不同等级蒸汽供给给蒸汽管网,蒸汽管网供给给其他用户,还有一部分供给给电厂发电,电厂的剩余蒸汽会回收到蒸汽管网。多余的部分存储到煤气柜。
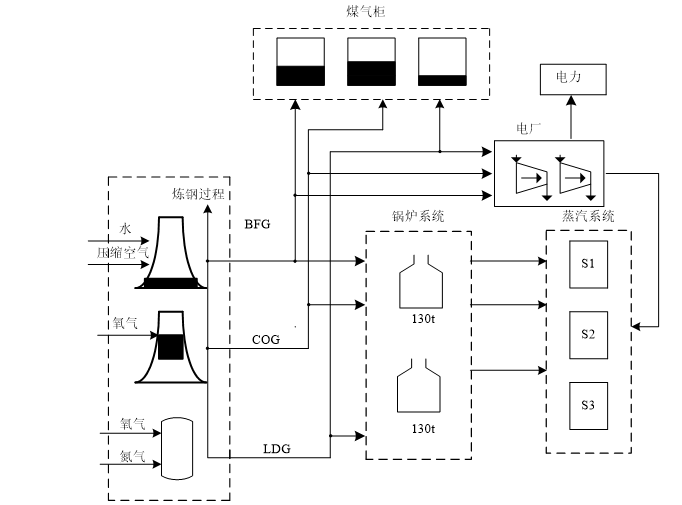
附图 某钢厂能源系统图
3 基于主成分分析的数据特征提取
主成分分析法在提取大数据典型特征具有较广泛的应用,对于钢铁生产过程中数量庞大的数据,建立典型场景的关键是选择数据信息较大的变量。
主成分提取步骤:
(1)


4 基于k-means聚类算法的场景建模及评估
本文使用k-means算法的思路是将多采样得到的多场景数据集划分为若干类,通过欧式距离测量经过主成分分析后各个场景之间的距离大小,各场景到该聚类中心的距离如果是最小,则认为该场景属于该类别(这里将离群点的数据删除)。
4.1 k-means聚类算法的原理
k-means聚类算法是划分聚类算法中比较经典的[4]。算法的基本思路是设置k个最适合的中心点,把最接近它们的点归为一类,其中寻找最佳聚类数k需要通过迭代的方式来寻找。例如将一个样本集划分为k个类别:(1)挑选初始聚类中心,一般通过随机的方式选择初始聚类中心。(2)迭代过程中,求每个样本到聚类中心的距离,到某一聚类中心距离最短则归为该类别。(3)选择适当的方法更新聚类中心,以找到较优的聚类中心。(4)迭代过程中重复(2)(3)步骤到满足条件为止。
4.2 聚类个数的确定
在聚类算法中k的值是未知的,为了找到最佳k值,采用聚类评价方法,通过聚类个数k的改变,在聚类指标取较好值时,当前k值为聚类数目。k的范围满足式(7)。

4.3 聚类算法步骤
(1)输入钢铁生产场景数据集,并进行数据特征分析挑选具有代表性的变量。
(2)删除场景数据集中代表性低的数据,然后对剩下的数据进行标准化。
(3)使用主成分分析挑选具有代表性的场景数据集,以达到降低数据维度的目的。
(4)设定初始聚类数目,同时选择初始聚类中心,计算每个类别的平均值作为新的聚类中心,让后用k-means算法进行聚类。
(5)观察所选聚类数目是否比较良好,若不合理,改变聚类数k重新聚类,重复上一步骤,直到寻找到较优的k值。
(6)聚类过后的场景与实际生产场景进行比较,观察其数据范围是否在实际场景的范围内。
(7)输出满足条件的场景
5 实例分析
该实例数据来源于某钢厂高炉实际生产数据,每小时进行一次采样,共采样得到上百组数据,采用上面介绍的方法。对场景提取的结果与实际生产时的场景进行比较,验证了所建立的场景具有代表性。
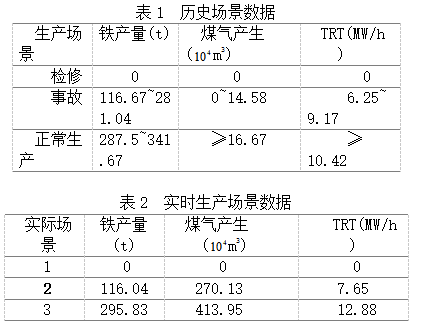
本文仿真中的1、2、3号场景分别代表检修、事故、正常生产。表1是通过历史数据聚类得到的场景;表2是将实际生产数据输入得到的场景数据,通过对实时生产场景数据的仿真,验证实际生产时产生表1的三种场景时能源数据是否在表1的数据范围内。实际生产场景数据如表1所示,对实时生产输入场景数据仿真如表2所示。
6 总结
本文针对钢铁生产过程多场景进行分析与模型的建立,对于钢铁生产过程中场景复杂的特点,对于生产过程的多维度和多尺度数据,采用主成分分析的方法提取数据特征,验证了该方法的有效性。利用DB指标和CH指标来进行评价的方法以解决最佳k值的确定问题。通过对实时生产数据的分析处理,验证了建立的场景与实时生产场景的对应性。最后,建立典型场景模型有助于日常生产对异常生产情况的提前预知和依靠人工进行检查时的经验不足等问题。
参考文献:
[1]蔡九菊,王建军,陆钟武,殷瑞钰. 钢铁企业物质流与能量流及其相互关系[J]. 东北大学学报, 2006(09):979-982.
[2]孙彦广,梁青艳,李文兵,贾天云. 基于能量流网络仿真的钢铁工业多能源介质优化调配[J]. 自动化学报, 2017,43(06):1065-1079.
[3]解素雯. 基于主成分分析与因子分析数学模型的应用研究[D]. 山东理工大学,2016.
[4]段云琦. 基于数据挖掘的电网规划多场景建模研究[D]. 华北电力大学(北京),2018.
[5]王玲玲. 基于场景分析法的含风电机组配电网无功优化[D]. 上海交通大学,2018.
[6]张立军,高春晓. 基于k-means聚类与粗糙集算法的指标筛选方法研究[J]. 运筹与管理,2020,29(12):8-12.
[7]D. L. Davies and D. W. Bouldin, A Cluster Separation Measure[J]. In IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. PAMI-1, no. 2, pp. 224-227, April 1979, doi: 10.1109/TPAMI.1979.4766909.
[8]Calinski T, Harabasz J. A dendrite method for cluster analysis[J]. Communications in Statistics, 1974, 3(1): 1-27.
作者简介:
胡宏涛,张子恒,吴定会






共0条 [查看全部] 网友评论